The mental model in action
From whiteboard to working Go backend . I put the four lenses to work with Claude Code agents and a layered architecture .
In my previous post , I shared a mental model for backend systems . Four lenses , four layers , a common language for humans and agents alike .
Go has been my go-to backend language for the past few years , so naturally I wanted to put the model to work there . claude-go-playground is the result . I built the gRPC variant with Claude Code agents guided by the model . The Connect-RPC variant follows the same architecture and is there for people to tinker with .
The setup
The repo contains two independent Go projects :
connect-rpc-backend/ # Connect-RPC project
grpc-backend/ # gRPC projectBoth follow the same layered structure . The specific tools I picked are less important than the questions that guided the choices :
- How do we define and enforce API contracts ? Protobuf .
- How do we keep SQL type-safe and auditable ? sqlc .
- How do we version the database schema ? goose .
- How do we guarantee async work happens if and only if the transaction commits ? RiverQueue .
- How do we run everything with a single command ? make .
You could swap any of these . Use SQLX instead of sqlc , atlas or flyway instead of goose , a message broker instead of RiverQueue , Taskfile instead of make . The architecture doesn’t change . What matters is that each question has a clear answer , and your agents know what it is .
The codebase layers map directly to directories :
cmd/server/ APP bootstrap , wiring , configuration
internal/api/ API handlers , proto mapping , routing
internal/domain/ DOMAIN business logic , transactions , canonical store
internal/outbox/ OUTBOX async event processing , data projectionsIf you read the previous post , this should look familiar . The whiteboard diagram became a directory tree .
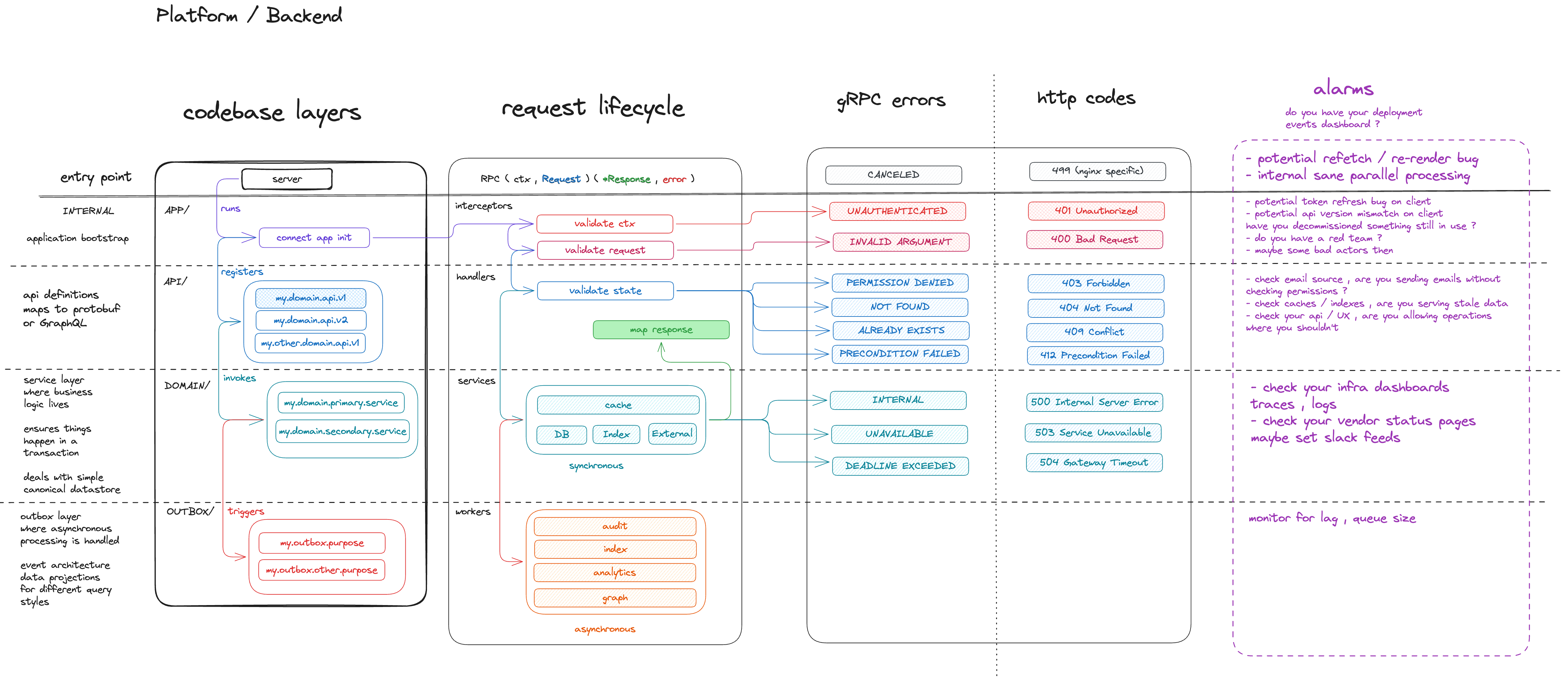
Agents that know their layer
Here is where it gets interesting . I didn’t just use the mental model to organise code . I used it to organise agents .
Six build agents , each targeting a specific layer with a specific concern :
do-scaffoldtargets APP . Project skeleton with empty stubs .do-prototargets API . Protobuf definitions for a domain .do-entity-storetargets DOMAIN . SQL migrations and sqlc queries .do-domaintargets DOMAIN . Business logic operations .do-integratetargets API + OUTBOX . Handlers , outbox workers , wiring .do-testtargets all layers . Unit and integration tests .
The agent doesn’t drift because it can’t . The mental model is baked into its instructions . Let me walk through each one .
do-scaffold
The foundation agent . Project skeleton , shared packages , server entry point . Compiles , boots , serves /health , and does nothing else .
Shared concerns live in pkg/ , business-agnostic by design . The bootstrap in cmd/server/ wires everything but owns no logic . pkg/ can eventually be extracted into a shared module .
See Code organisation for more details .
PR question : does the structure match our architecture ?
do-proto
Defines the API contract for a domain . Three proto files : resource model , typed ID references , service definition . Validation lives at the boundary using buf.validate , consistent API patterns everywhere .
See Protobuf for more details .
PR question : is the API contract right ?
do-entity-store
Translates the proto contract into postgres . Each domain gets its own schema . Soft deletes everywhere . Partial updates use COALESCE so unset fields are never overwritten .
PR question : is the data model right ?
do-domain
Business logic , one file per operation . Every write follows the same path : begin tx , query , emit events , commit , cache . The outbox events are part of the transaction , not an afterthought . If the transaction rolls back , the events never fire .
Errors are layer-scoped . Sentinel errors like ErrNotFound get mapped to RPC codes by the handler above .
See Error handling and Transactional outbox for more details .
PR question : is the logic correct ?
do-integrate
The wiring agent . Connects handlers to services , outbox workers to RiverQueue , both to the bootstrap . Each worker targets a specific concern : audit logging , search indexing , analytics projections . Explicit error mapping , clean boundary between proto and domain types .
See Code organisation and Transactional outbox for more details .
PR question : is this wired correctly ?
do-test
Integration tests at the API layer cover the full request lifecycle : interceptor validation , error mapping , handler logic , database queries , all with a real postgres via testcontainers .
Unit tests at the domain layer target specific business logic : precondition checks , state transitions , edge cases in isolation .
See Testing for more details .
PR question : is this adequately tested ?
Conventions that scale
A few patterns keep the codebase consistent across domains , regardless of which agent wrote the code : interface-first design , explicit dependency injection , file naming that signals intent , strict dependency rules between layers , validation at the boundary , and testing at the right granularity .
The full list is on the Go Best Practices page .
From reviewers to auditors
For every build agent , there is a matching review agent . One writes , another reviews . Code review becomes automated .
Our role shifts from reviewing diffs to auditing outcomes . Did the agent follow the blueprint ? The PR questions above are the audit checklist . That is how you build trust in AI .
What I learned
- Focused diffs . Layer-scoped agents touch one layer . One checklist , no surprises .
- Layered reviews . Give each reviewer a clear checklist . A layer-scoped agent verifies the blueprint . A general-purpose reviewer like Copilot catches what falls outside the established structure . Different contexts , sharper feedback .
- Evolve after every PR . Treat your build and review agents as living documents . After each PR , reflect on what worked and what didn’t . Consider a
do-reflectagent that maps into your team’s retrospectives , capturing improvements back into the agent instructions .
Try it
The repo is open . Clone it , pick a framework , scaffold a domain , and watch the agents work through the layers . The CLAUDE.md at the root has everything you need to get started .
The mental model from the previous post isn’t just a diagram . It’s an operating system for your agents .
What about changing what already exists ?
Build agents create new code . But what about changing existing code ? Can the same layer-scoped approach produce refactor agents that break large changes into incremental , structured PRs ?